Быстрый старт
Если вы хотите без излишней информации начать общение с персонажем, то этот раздел для вас. Для начала выберите, какие языковые модели вы будете использовать - облачные (Character AI, Mistral AI, Open AI, OpenRouter или прокси) или локальные решения.
Содержание раздела
Выбор LLM
Для облачных моделей
Для начала вам нужно перейти на вкладку настроек и вписать API-токен от нужной платформы.
Для Character AI
- Перейдите на сайт Character AI и авторизуйтесь
- Нажмите на F12 и перейдите в Инструменты разработчика
- Откройте вкладку Сеть, выберите любой адрес, в котором есть neo.character.ai или api.character.ai
- Чуть ниже вы увидите поле Authorization, копируйте то, что идет после слова Token - это ваш API-токен от сайта
- Вставляйте его в специальное поле в Soul of Waifu
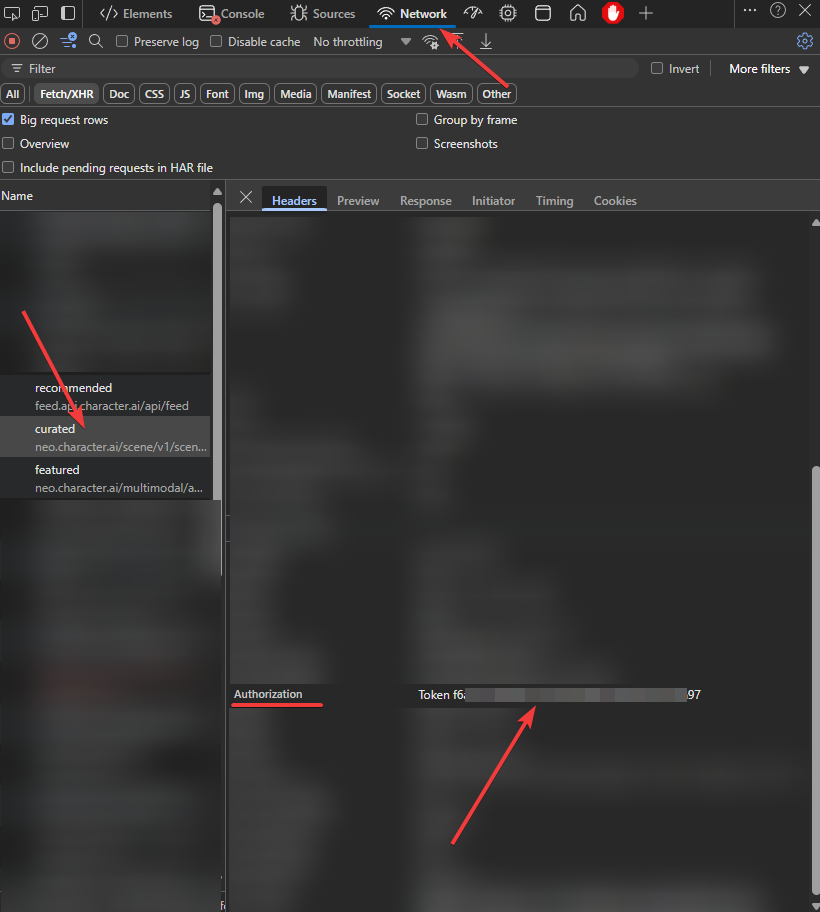
Поиск токена в Developer Tools браузера
Для Mistral AI
- Перейдите на сайт Mistral AI и зарегистрируйтесь там
- Перейдите на вкладку API keys и создайте ключ
- Скопируйте значение токена и вставьте его в программу
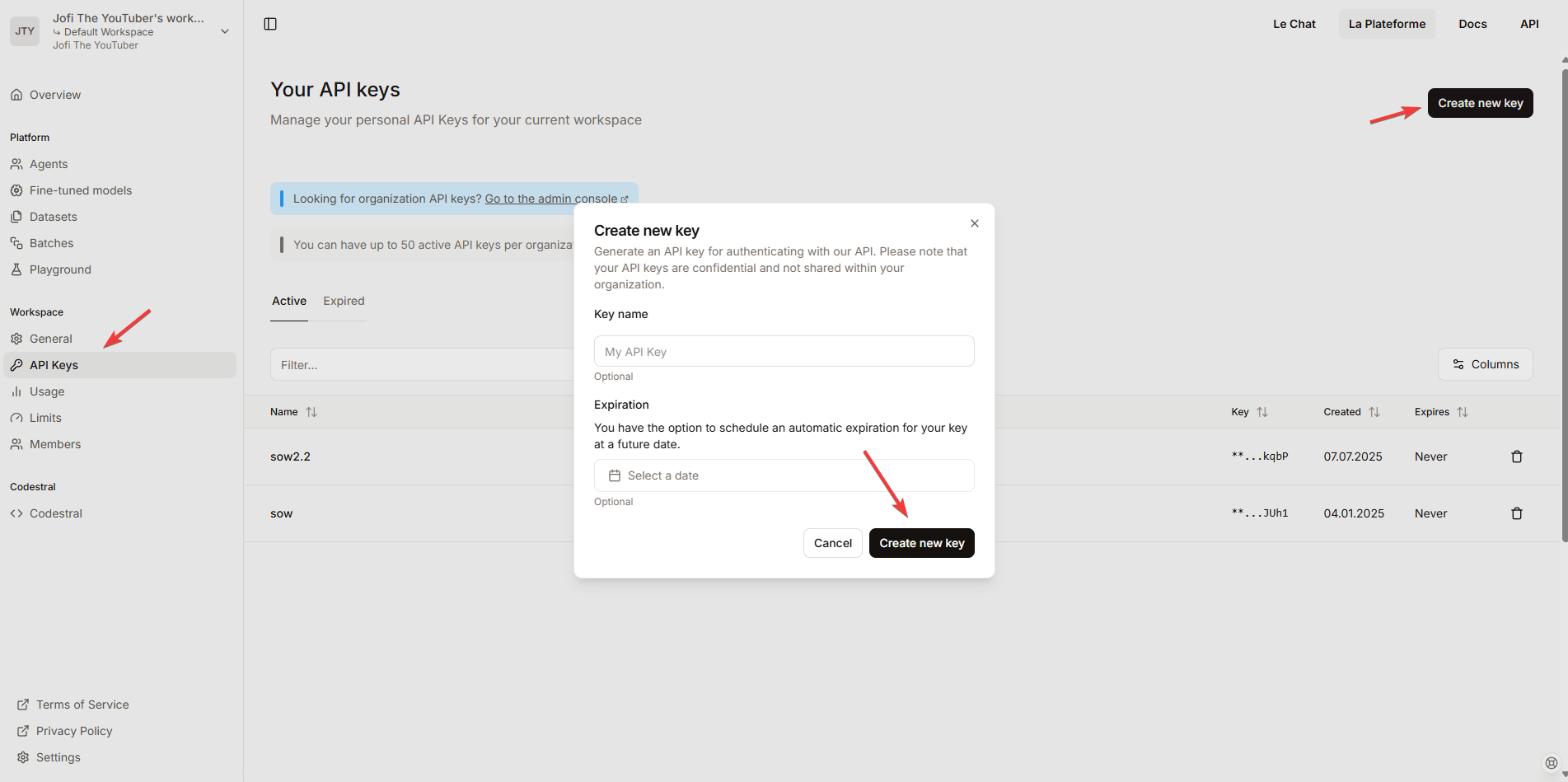
Создание API ключа Mistral AI
Mistral AI также требует, чтобы вы указывали модель, которую будете использовать через API. Их можно посмотреть на сайте с документацией к API от Mistral AI. По умолчанию в Soul of Waifu используется вышедшая в июне 2025 года модель, которую люди сильно хвалят.
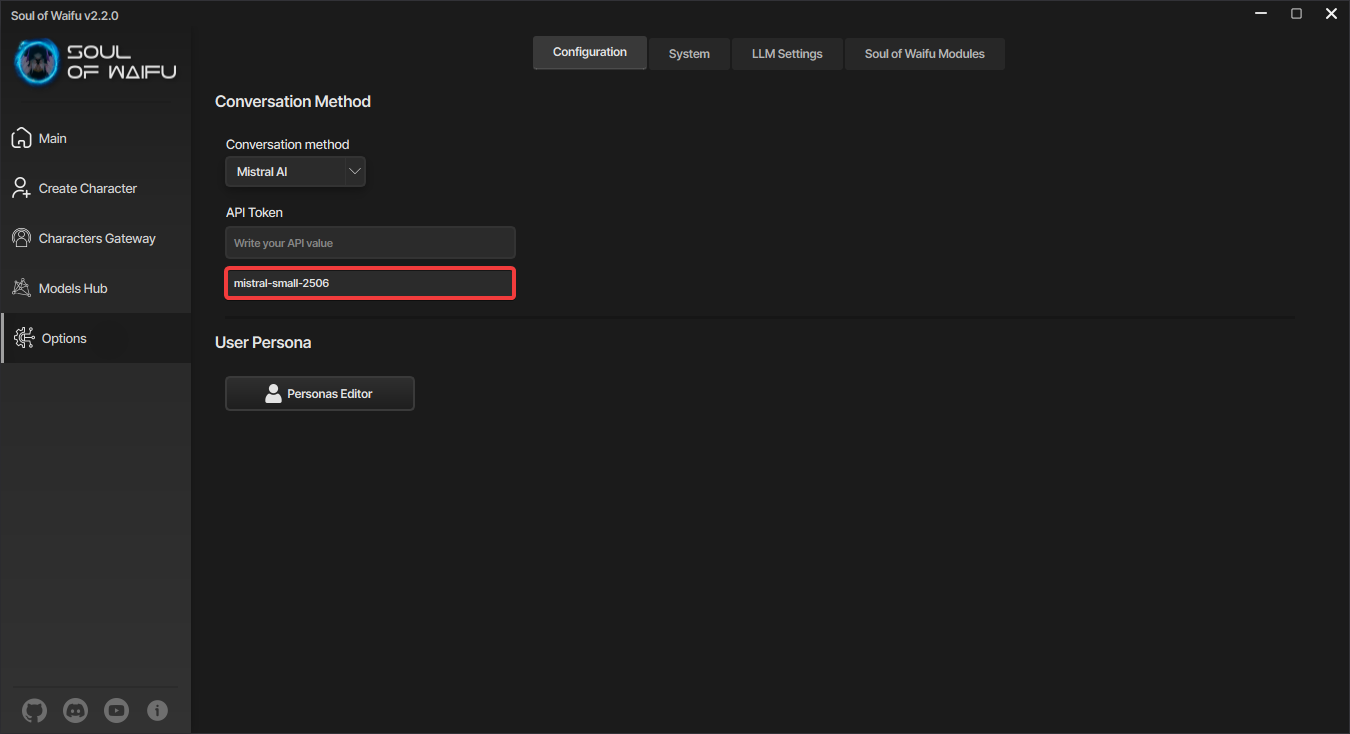
Выбор модели Mistral AI
Для Open AI
Помимо самого ключа от Open AI, можно использовать OpenAI-like прокси, а также сторонние программы для запуска сервера с загруженной в неё языковой моделью. Например, LM Studio, и оттуда вы можете вставить кастомный эндпоинт в Soul of Waifu.
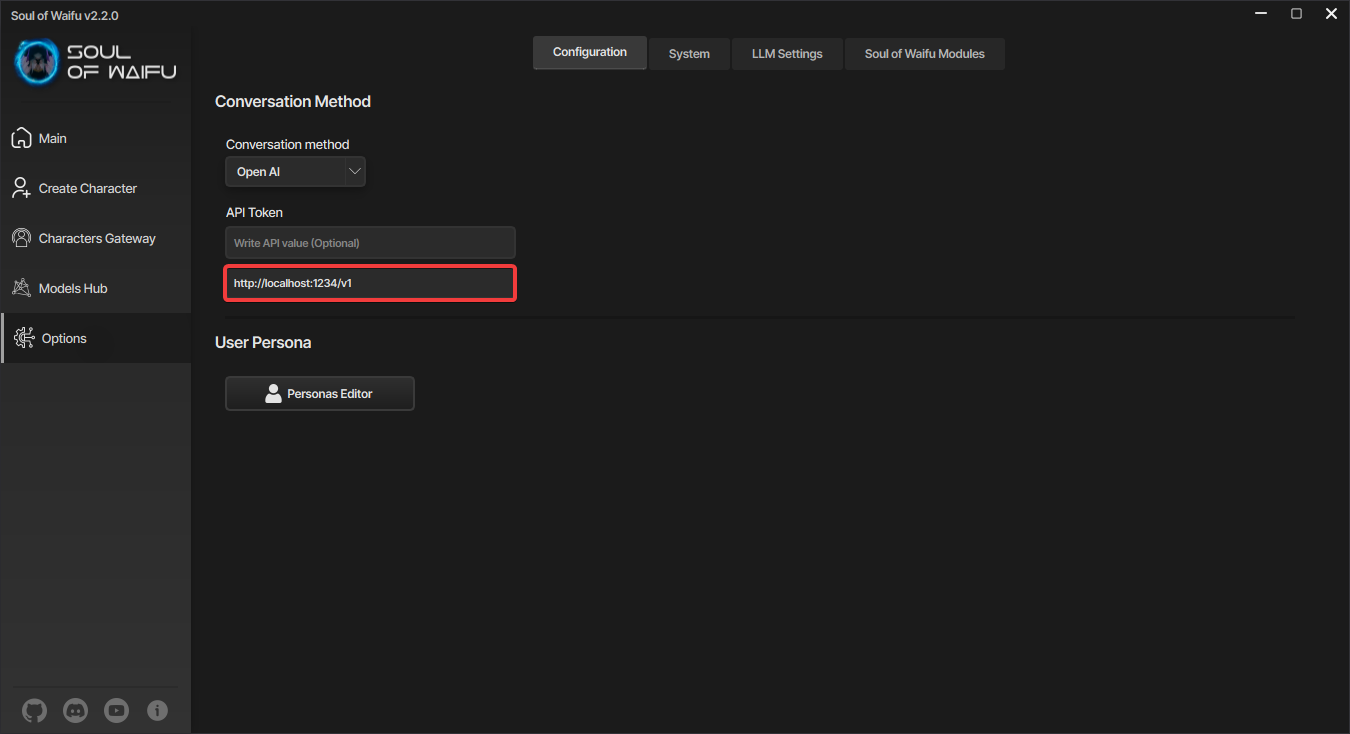
Область для вставки API от OpenAI
Для OpenRouter
- Перейдите на сайт OpenRouter, зарегистрируйтесь и переходите на страницу создания API-ключа
- Дайте ей имя и скопируйте значение в Soul of Waifu
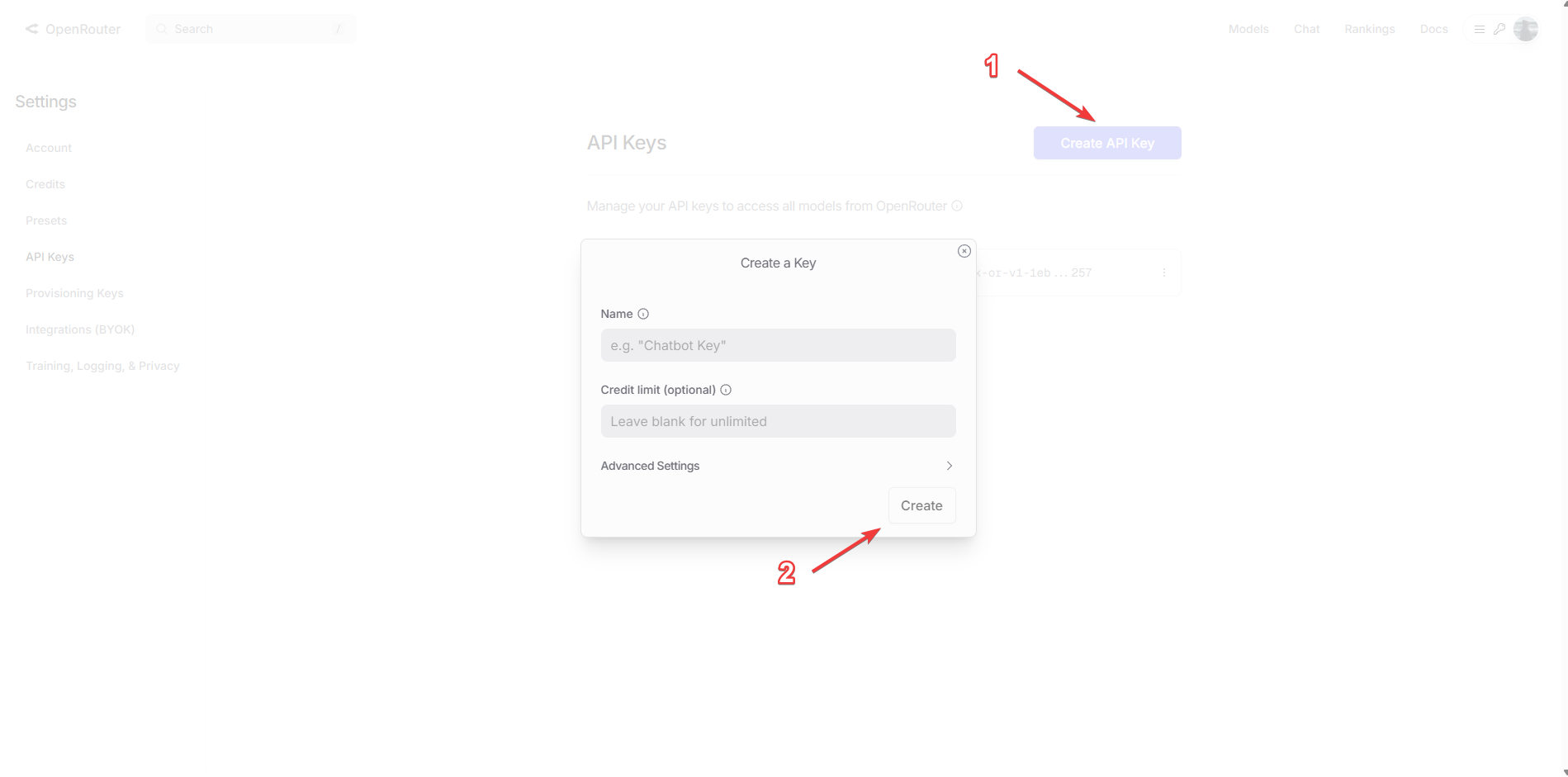
Создание API ключа OpenRouter
OpenRouter примечателен тем, что он позволяет использовать разные языковые модели через свой API, но за них надо платить. Если вы хотите использовать возможности OpenRouter бесплатно с ограничениями по количеству обращений к API, то в Soul of Waifu вам надо будет выбрать нужную модель с пометкой free. Например, DeepSeek V3 0324 (free).
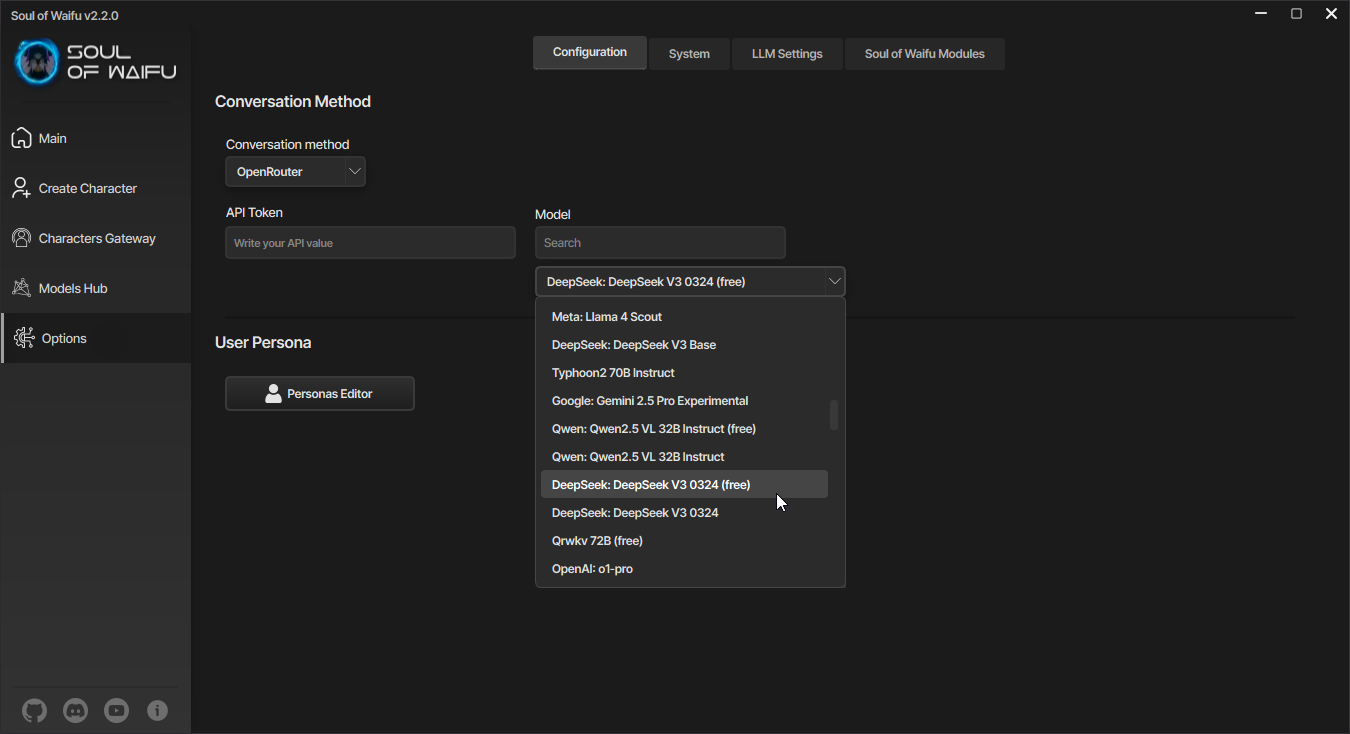
Выбор модели OpenRouter
Для локальных моделей
Локальный вариант отличается от облачных решений тем, что требует загрузки самой модели на компьютер, а значит вам надо будет найти под неё место. Помимо этого, вам нужно осознавать тот факт, что ваш компьютер может не потянуть ту или иную модель.
Главным преимуществом локальных языковых моделей является отсутствие на некоторых из них цензуры, а также то, что никто не сможет просмотреть ваши чаты с персонажами, все данные остаются у вас.
Системные требования (для квантования Q4_K_M)
| Модель | Параметры | VRAM (GPU) | RAM (CPU) | Контекст 4K |
|---|---|---|---|---|
| Модель 7B | 7 миллиардов | 5-6 ГБ | 14-16 ГБ | +1.5 ГБ |
| Модель 13B | 13 миллиардов | 9-10 ГБ | 28-32 ГБ | +2.5 ГБ |
| Модель 30B | 30 миллиардов | 20-24 ГБ | 60-64 ГБ | +5 ГБ |
| Модель 70B | 70 миллиардов | 40-48 ГБ | 96-128 ГБ | +10 ГБ |
Ключевые рекомендации:
- Модель 7B - отлично работает на RTX 2060/3060 (6 ГБ) или CPU с поддержкой AVX2 и 16 ГБ RAM. Подходит для ноутбуков и офисных ПК.
- Модель 13B - требует RTX 3080/4070 (10–12 ГБ) или Ryzen 7 / Intel i7 + 32 ГБ RAM. Отличный баланс качества и скорости.
- Модель 30B - нуждается в RTX 3090/4090 (24 ГБ) или системе с двумя CPU и 64 ГБ RAM. При контексте 32K дополнительно требуется +8–12 ГБ памяти.
- Модель 70B - подходит только для высокопроизводительных рабочих станций с 48+ ГБ VRAM или 96+ ГБ RAM.
Некоторые уточнения:
- Квантование:
- Q4_K_M: оптимальный выбор - сохраняет до 99% качества оригинала при минимальном размере. Формат по умолчанию для большинства.
- Q6_K_M: рекомендуется при наличии запаса памяти. Качество близко к FP16, размер увеличивается на ~50%.
- Q3_K_M: максимальная экономия памяти, но с потерей качества до 15–20%. Подходит только для слабых систем.
- MLOCK: Фиксация модели в RAM:
- Ускоряет ответы на 15–30% за счёт отсутствия подкачки.
- Требует +20–30% к указанному объёму RAM.
- Рекомендуется включать при использовании CPU-инфера.
- Контекстное окно: Память на контекст зависит от длины:
- GPU: +0.5–1 ГБ VRAM на каждые 1000 токенов контекста.
- CPU: +1–1.5 ГБ RAM на каждые 1000 токенов контекста.
- Пример: при контексте 32K потребуется дополнительно 16–32 ГБ RAM.
- Процессор:
- Обязательна поддержка AVX2 (Intel 2011+, AMD 2015+).
- Без AVX2 производительность падает в 3–10 раз.
- Оптимизации:
- Flash Attention: снижает потребление VRAM на 20-30% при длинных контекстах (8K+)
- Разделение слоёв (offloading): позволяет загружать часть модели на GPU, остальное - в RAM.
- Использование NVMe SSD: ускоряет загрузку моделей на 30–50%.
Примечание: Указанные значения VRAM/RAM - ориентировочные. Фактическое потребление зависит от реализации (в случае Soul of Waifu - это llama.cpp), размера контекста и контекстного окна, версии драйверов, выбранного кванта и так далее. Рекомендуется иметь запас памяти не менее 10–15% от размера модели.
Как только вы определились с выбором модели, переходите на вкладку Хаб моделей и набирайте в поиске её название. Нажмите на скачать модель и выбирайте нужный квант. Что такое кванты вы сможете посмотреть в "Вводном курсе в AI RP" позже, а пока я вам рекомендую выбирать Q4_K_M, так как они наиболее сбалансированные. Если у вас уже есть файл с моделью, переместите её в папку assets/llm_models.
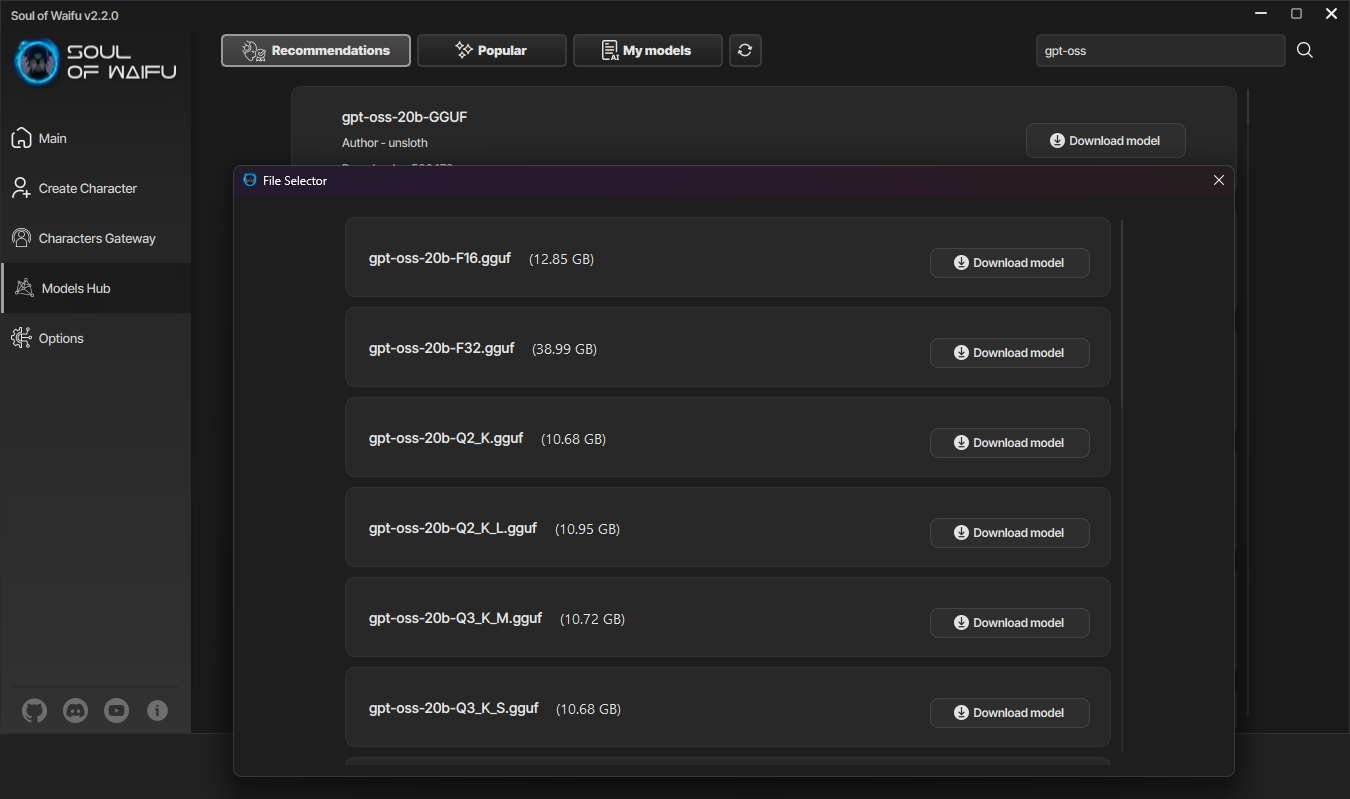
Интерфейс Хаба моделей
Прогресс скачивания вы сможете увидеть только при запуске с консолью, имейте это в виду. После того как модель скачалась, переходите в настройки программы и в настройках LLM выберите устройство, на котором хотите запустить модель. Это может быть процессор или видеокарта. У видеокарты не забудьте выбрать нужный бэкенд - CUDA для видеокарт NVIDIA или Vulkan для всех остальных.
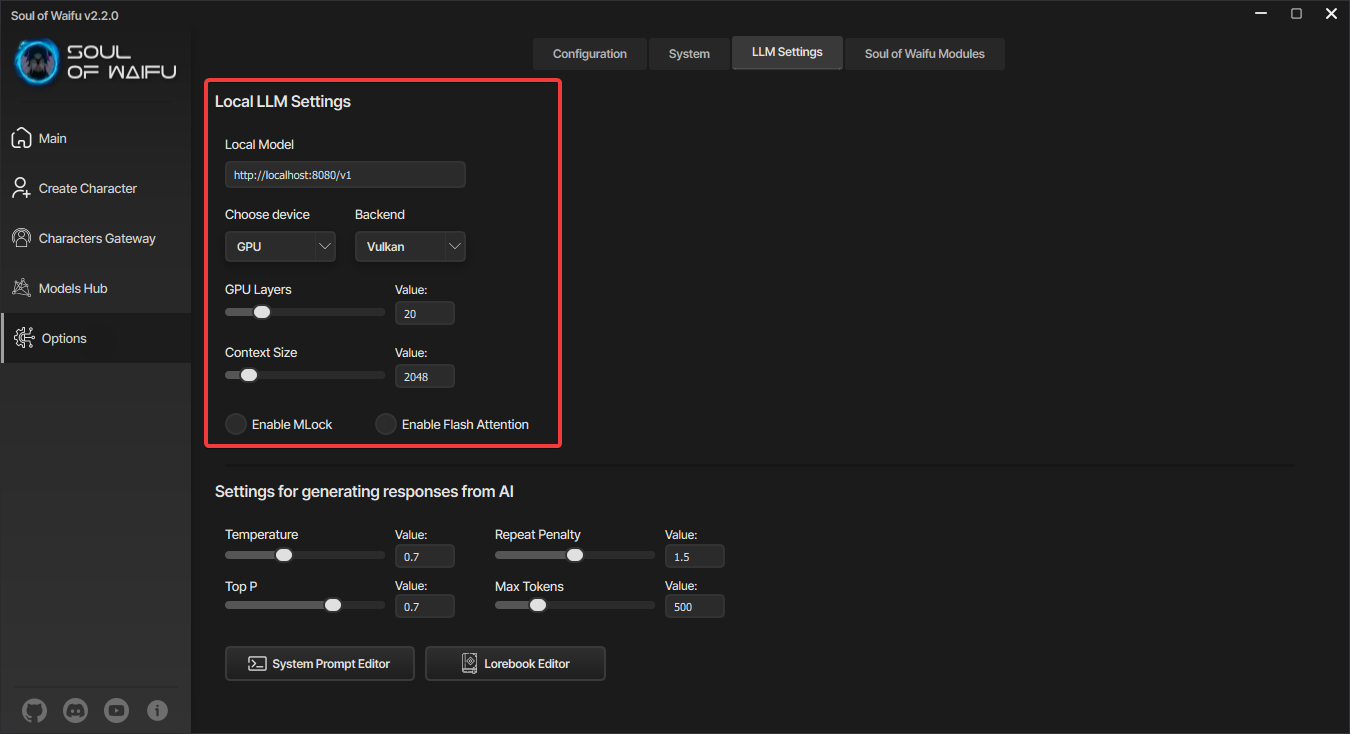
Настройки локальной языковой модели
Теперь возвращайтесь обратно в Хаб моделей, где вы увидите свою недавно загруженную модель. Запускайте её и ждите, пока она загрузится в систему. Поздравляю, теперь вы можете использовать локальные языковые модели в Soul of Waifu. При необходимости сменить модель, сначала выгрузите предыдущую из системы при помощи кнопки на боковом меню, а потом уже запускайте новую.
Создание персонажа
Теперь нам нужен какой-нибудь персонаж, чтобы начать с ним общаться. Для этого нажмите на "Создание персонажа" в боковом меню и выберите нужный метод общения. После нажатия на кнопку вы перейдёте в редактор карточки персонажа.
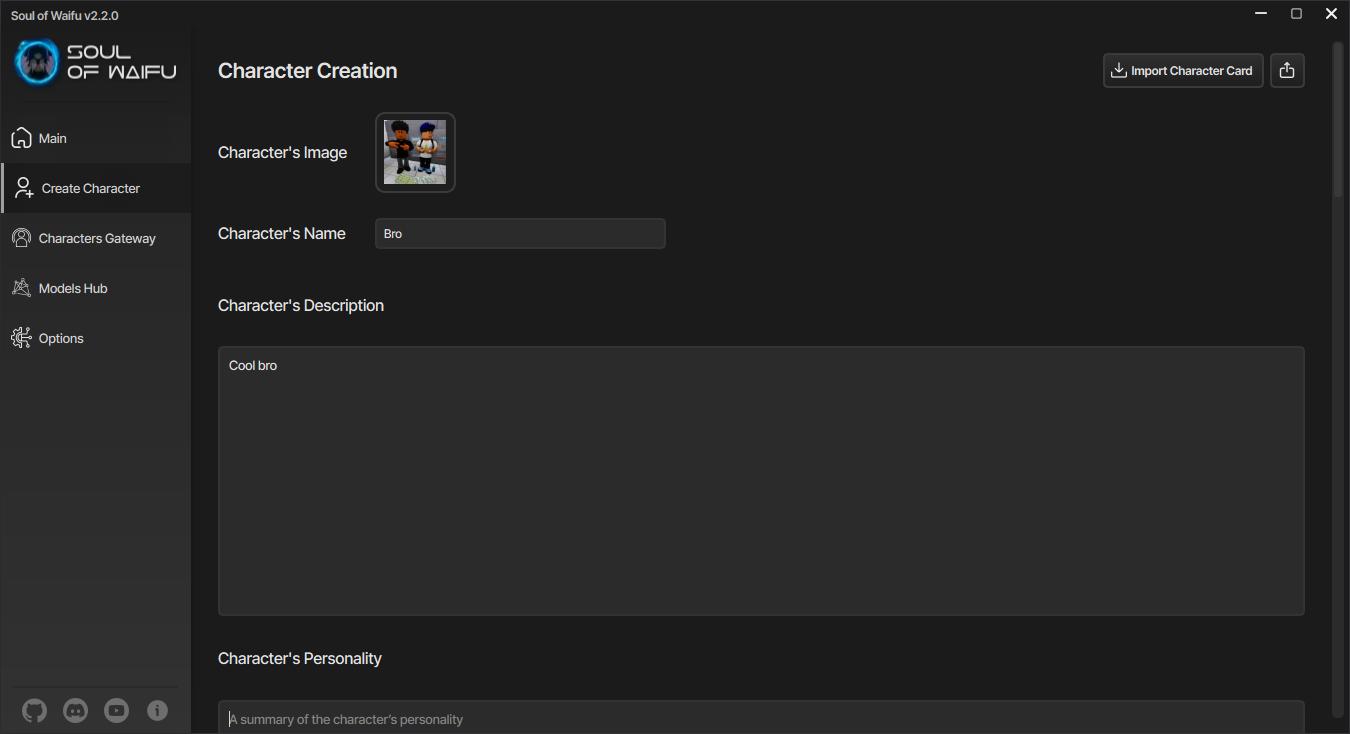
Редактор персонажа с основными полями
Тут вы можете назначить персонажу аватар, имя, описание, личность, сценарий, первое сообщение, примерные сообщений, альтернативные приветствия (они же альтернативные первые сообщения), заметки создателя, версию карточки и позже выбрать персону, пресет системного промпта и лорбук.
Самыми важными полями при создании персонажа являются имя, описание и первое сообщение, чтобы персонаж имел хоть какую-то личность, на которую сможет опираться языковая модель.
Soul of Waifu Hub
После того как вы написали всю необходимую информацию о персонаже нажмите на кнопку "Создать персонажа". Карточка персонажа автоматически появится в списке персонажей в главном меню. Нажмите на неё, чтобы перейти в чат. Напишите сообщение, отправьте его персонажу и наблюдайте, как он вам отвечает.
Чтобы узнать больше о взаимодействии с персонажами, продолжайте читать документацию.