Настройка моделей
В этом разделе мы рассмотрим все параметры, которые можно изменить у языковых моделей, чтобы повлиять на генерацию текста. Для того, чтобы изменить настройки языковых моделей, перейдите в настройки и там выберите "Настройки LLM". Вы попадёте в настройки языковых моделей. В верхней части находятся настройки локальных языковых моделей, а в нижней части - для всех языковых моделей, как облачных, так и локальных.
Содержание раздела
Настройка модели в программе
Если вы захотите использовать локальную языковую модель в других приложениях или играх, запустите свою локальную языковую модель через Хаб моделей и скопируйте адрес, к которому может обращаться игра, чтобы генерировать текст. Например, в игре My Robot для того, чтобы общаться с роботом, необходимо подключить языковую модель. Благодаря Soul of Waifu вы можете подключить запущенную в программе модель к игре и таким образом робот сможет с вами общаться.
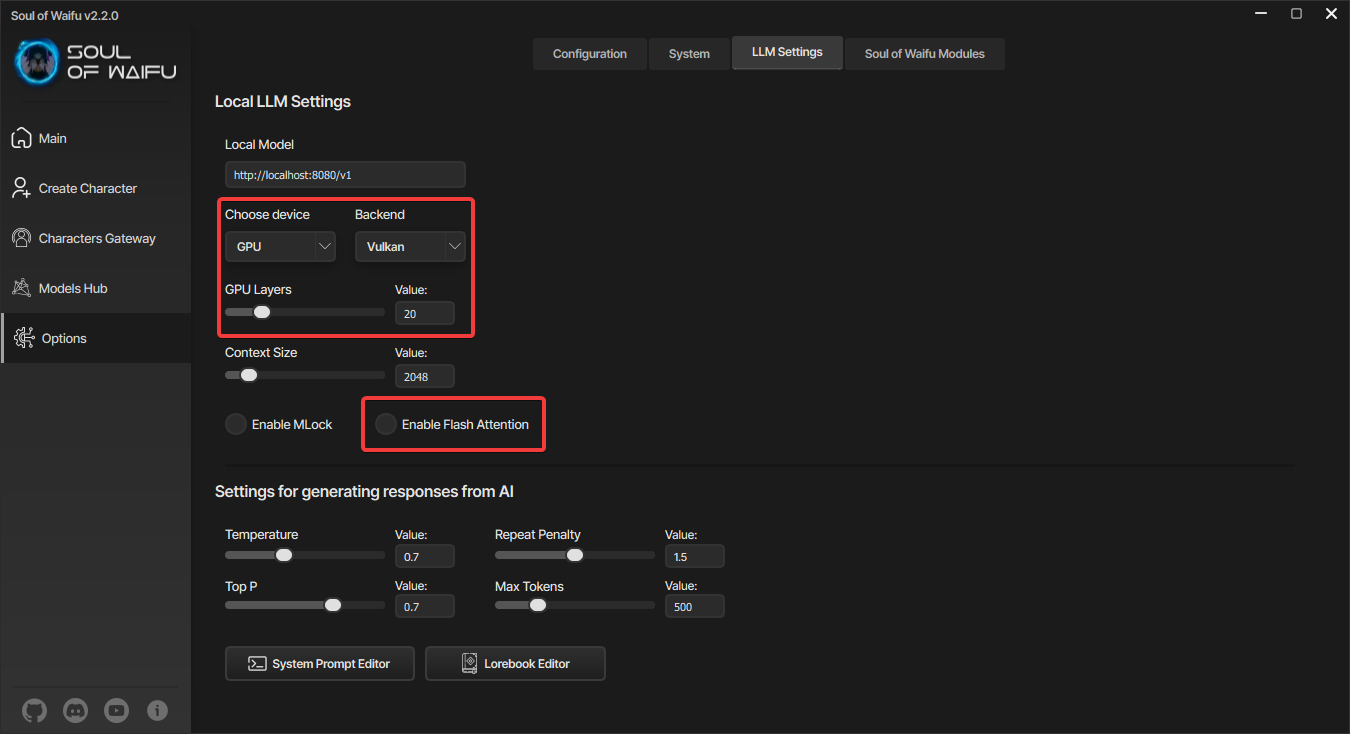
Настройки языковых моделей для видеокарт
Робот в игре My Robot
Выбор устройства
Следующая настройка отвечает за выбор устройства, на котором будет происходить генерация текста - процессор или видеокарта. На процессоре генерация токенов будет происходить гораздо медленнее, чем на видеокарте, но зато вы сможете запускать локальные языковые модели даже на старых системах, хоть и с ограничениями по скорости.
Если вы выбрали видеокарту, то следующим шагом будет выбор бэкенда. Тут всё достаточно просто - если у вас видеокарта NVIDIA, то выбирайте CUDA, а если что-то другое, то выбирайте Vulkan. С поддержкой CUDA ядер скорость генерации текста несколько выше, чем при использовании Vulkan, но главное, что будут поддерживаться любые видеокарты.
GPU Layers
Это количество слоев модели, которые будут обрабатываться на GPU. Диапазон от 0 до максимального количества слоев. Если у модели всего 35 слоев, тогда даже если вы введете 1000, в видеокарту загрузятся все слои модели, то есть 35. По умолчанию видеокартой будут обрабатываться 20 слоев локальной языковой модели, это обеспечивает баланс между скоростью и качеством вывода. Чем больше слоев на GPU, тем выше скорость генерации токенов, но для этого требуется больше видеопамяти.
Context Size
Это максимальная длина контекста (количество токенов), выделенных модели для обработки информации. Она включает в себя всю информацию с карточки персонажа, системный промпт, лорбук, авторские заметки и историю чата (все сообщения в чате). Обратите внимание, что модель учитывает за один запрос ровно столько токенов, сколько указано в параметре Context Size, и это значение применяется при запуске модели. Изменения в настройке не вступают в силу, пока модель не будет перезапущена. Если некоторая информация о персонаже или о чате выходит за рамки контекстного окна, модель забывает её и больше не может ею оперировать.
MLock
Эта настройка отвечает за фиксацию языковой модели в оперативной памяти насильно, что предотвращает выгрузку модели из кэша, ускоряя последующие запросы к ней. Но включать её надо только в том случае, если у вас много свободной оперативной памяти.
Flash Attention
Отвечает за оптимизацию механизма внимания, ускоряя вычисления. Он снижает время генерации ответов от персонажа за счёт более эффективного распределения вычислительных ресурсов вашего компьютера. Если у вас видеокарта от NVIDIA, обязательно её включайте. Более подробно об этой технологии вы сможете узнать в "Вводном курсе в AI RP".
Общие настройки языковых моделей
Теперь переходим к общим настройкам языковых моделей как облачных, так и локальных.
Температура
Отвечает за уровень случайности и предсказуемости генерируемого текста. При генерации следующего токена модель вычисляет вероятности для всех возможных вариантов. При низкой температуре (от 0.1 до 0.5) модель выбирает наиболее вероятные варианты, ответы становятся детерминированными, технически точными. При средних значениях (от 0.6 до 0.9) проявляется баланс между логичностью и креативностью ответов, в большинстве случаев именно эти значения будут хорошо работать в диалогах. При высоких значениях (от 1.0 до 2.0) ответы становятся нестандартными, хаотичными, модель перестает следовать заданной инструкции.
Top P
Регулирует порог вероятности для выбора следующего токена, определяет, сколько вариантов модель будет учитывать при генерации. Модель сортирует все возможные токены по убыванию вероятности, затем через параметр Top P задаётся кумулятивная вероятность. Например, если значение Top P = 0.9, тогда модель будет брать токены, суммарная вероятность которых составляет 90%, а остальные 10% отбрасываются. Чем меньше значение, тем более однообразные сообщения получаются при генерации.
Repeat Penalty
Отвечает за степень подавления повторяющихся слов или фраз. Если значение > 1.0, вероятность повторения уже использованных токенов понижается. При значении 1.0 повторы остаются без штрафования. Однако слишком высокие значения могут сделать текст неестественным, так как даже повторяющиеся местоимения будут отбрасываться при генерации. Рекомендую ставить значения от 1.3 до 1.5, чтобы ответы не повторялись.
Max Tokens
Регулирует максимальную длину генерируемого ответа (в токенах). Как мы знаем, токен - это минимальная единица текста (слово, часть слова, знак препинания). Модель останавливает генерацию текста, как только достигает лимита заданного в настройках, даже если ответ не был логически завершён.
На следующей странице вы сможете ознакомиться с разными Text-to-Speech системами, которые поддерживает Soul of Waifu с примерами.